A Simple Real-World Analogy

Image: News18
Picture a Mumbai local at peak hour. The train pulls in, doors open, and right then hundreds of people rush for the same few doors. Everyone was waiting for that one moment. Everyone moves at once. The doors and the platform become the bottleneck. It’s not that the crowd is so the crowd might be big, but the real issue is they’re all hitting the same narrow point at the same time. Chaos, delays, and sometimes worse.
In systems, the thundering herd is the same idea: many clients or requests “wake up” or react at the same time and hit the same resource: a cache, a database, or a server. All at once. One shared resource, one synchronized moment, and suddenly the system is overloaded. Once you see that pattern, you can start designing around it.
What Is the Thundering Herd Problem?
The thundering herd problem is when a large number of clients or processes all try to use the same shared resource at the same time. It’s not just “high traffic.” It’s traffic that’s synchronized: everyone wakes up, retries, or reacts at once (for example, when a cache entry expires, a lock is released, or a timer fires). They all hit the same bottleneck together. That burst can overload the resource, slow everything down, or take the system down.
The name comes from the idea of a herd of animals stampeding in the same direction. In software, the “herd” is your requests or workers, and the “stampede” is them all going for the same cache, database, or server at once. Once you know what to look for, you’ll see this pattern in caching, databases, load balancers, and more.
Where It Commonly Occurs
The same pattern shows up in a few familiar places. Once you know what to look for, you’ll spot it in caching, databases, and load balancers.
Caching. Many requests depend on the same cache key. When that key expires or gets invalidated, they all miss at once and hit the backend or database together. Same key, same TTL, same moment. That’s a classic cache stampede (another name for the thundering herd in this context).
Databases. Here the herd often forms around a shared lock, a connection pool, or a single primary. When the lock is released or a failover happens, everyone retries or reconnects at the same time. One event, many clients, all hitting the same resource.
Load balancers. When a backend that was down comes back up, the load balancer may send a burst of traffic to it. Or many clients retry at once and land on the same node. Either way, one resource gets a synchronized spike.
Diagram created with Google Nano Banana
We’ll dig into the caching case next, since it’s the one you’ll see most often and it sets up the rest of the article.
A Small Architecture Example
A simple setup: your app talks to a cache (e.g. Redis or Memcached), and the cache sits in front of the database. When a request comes in, the app checks the cache first. If the key is there, it returns the value and the database is never touched. If the key is missing, the app fetches from the database, writes the result into the cache, and then returns it. The cache has a TTL (time to live): after some time, each key expires and is removed.
Here’s where the herd forms. Suppose a popular key (say, “homepage_config”) is cached with a 5-minute TTL. For those 5 minutes, every request is served from the cache and the database is idle. Then the key expires. The next request misses the cache and goes to the database. So does the one after that, and the one after that. In normal traffic that’s fine. But if you have many requests per second, they’re all missing the same key at the same time. They all go to the database at once. One expired key, one moment, many requests. That’s the thundering herd in the caching layer.
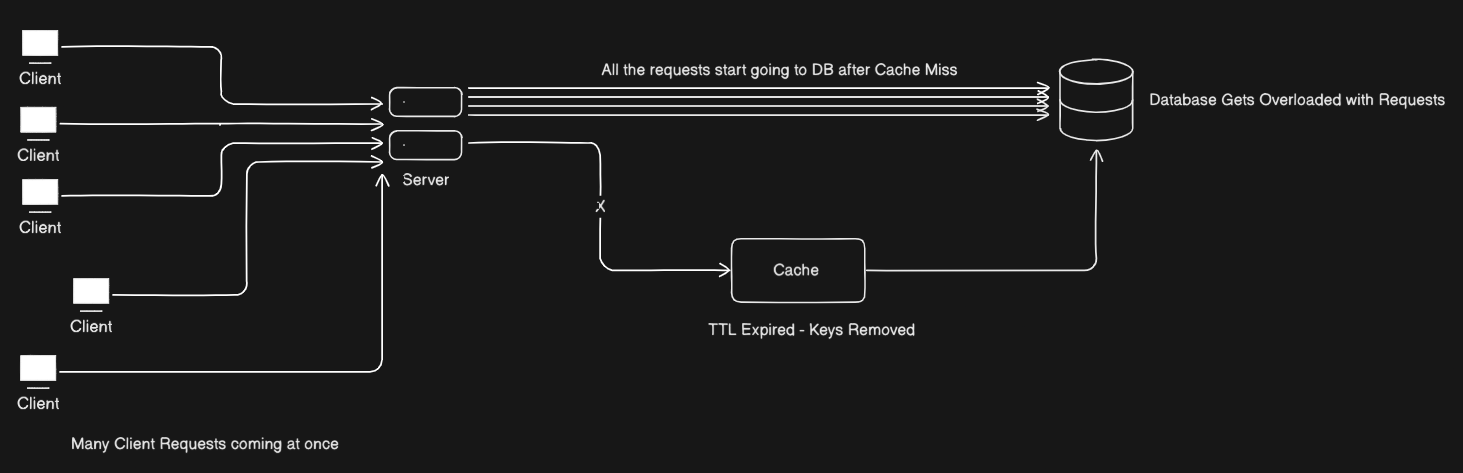
Tried creating myself :P
Real-World Examples: When It Actually Happened
Major tech companies have faced significant outages due to the thundering herd problem, often triggered by automated systems or sudden spikes in user demand. Here are four well-known examples.
1. Facebook (September 2010)
Facebook suffered a 2.5-hour global outage, its worst at the time. A routine configuration change was interpreted as invalid by an automated validation system. Every client saw the “invalid” value and simultaneously tried to fix it by querying the database. Each failed query led to the cache key being deleted, which triggered even more queries. The database locked into a 100% CPU loop. Engineers had to take the entire site offline to stop the stampede and let the database recover.
2. Shopify (Black Friday 2019)
During peak shopping, an 8-minute outage hit. A product recommendation cache expired right when traffic was extremely high. Roughly 47,000 concurrent requests hit the primary database within 3 seconds to regenerate the missing data. Database CPU spiked to 98%, response times ballooned, and the service went down.
3. Netflix (WebSocket connection recycling)
Netflix keeps millions of long-lived WebSocket connections for real-time communication. During new deployments, closing old connections all at once would cause a huge wave of simultaneous reconnection attempts to the new servers. Their fix: connection recycling with randomized lifetimes (typically 25–30 minutes) so reconnections are staggered over a wider time window instead of all at once.
4. PayPal / Braintree (Disputes API)
The Disputes API handles credit card chargebacks and heavy processing jobs. Large batches of jobs were queued in parallel and overwhelmed the downstream processor services. When the service slowed down, jobs retried at static intervals, creating a repeating cycle of failures that overwhelmed the system’s ability to autoscale. They adopted exponential backoff with jitter to desynchronize retries and break the convergence of requests.
Why It Becomes Dangerous in Distributed Systems
In a distributed system you have many clients, many servers, or many workers. When something triggers them at the same time (a cache expiry, a config change, a failover), they all react together. The herd isn’t one machine; it’s hundreds or thousands of processes hitting the same database, same cache, or same API at once. That scale is what makes the problem dangerous. There’s also a feedback loop: when the shared resource slows down, clients often retry or invalidate cache, which sends more traffic and makes things worse. The Facebook incident showed that clearly: each failed query led to cache deletion and more queries. In distributed systems, one bad trigger can turn into a system-wide stampede before you have time to react.
Impact
When the herd hits, the pain shows up in a few places. CPU on the overloaded resource (database, server) maxes out because it’s processing too many requests at once. The database in particular can lock up: too many connections, too many queries, and it spends all its time context-switching or waiting on locks instead of making progress. The cache might get hammered with misses and refill requests, or become useless if every key expires at the same time and everyone tries to repopulate at once. Latency goes up for everyone: requests queue, timeouts increase, and users see slow or failed responses. In the worst case, one overloaded component can cause cascading failures downstream. Keeping an eye on these four (CPU, database load, cache hit rate, and latency) helps you spot and debug a thundering herd in production.
Techniques to Prevent or Reduce It
You can’t stop traffic from spiking, but you can break the synchronization so the herd doesn’t hit all at once. Here are five common approaches.
-
Request coalescing — Merge requests for the same missing cache key: one request fetches from the DB and fills the cache, the others wait and then read from cache. One DB call instead of thousands.
-
Cache locking (mutex) — Before refilling a cache key, acquire a lock. Only the first request fetches and writes; others wait or get a stale value. When the first is done, the rest get a cache hit.
-
Staggered expiry — Add jitter to TTL (e.g. 5 min ± 30 seconds) so keys don’t all expire at once. Requests spread out over time. Netflix used this for WebSocket reconnections.
-
Exponential backoff (with jitter) — Retry with increasing delays (1s, 2s, 4s, …) plus random jitter so retries don’t line up. PayPal/Braintree used this on their Disputes API.
-
Rate limiting — Cap how many requests a client or service can send. Doesn’t fix the root cause but prevents a single burst from taking the system down and buys time to recover or scale.
In practice you often combine these (e.g. coalescing or mutex for cache refill, plus staggered TTLs and backoff for retries). The goal is always the same: desynchronize the herd.
Key Takeaways
-
The problem is synchronization, not just volume. A thundering herd is when many clients or requests hit the same resource at the same time. Same trigger, same moment. That’s what overloads the system.
-
It shows up in caching, databases, and load balancers. Cache expiry, lock release, failover, or retries can all create a synchronized burst. The Facebook, Shopify, Netflix, and PayPal incidents are proof that it happens at scale.
-
In distributed systems it’s worse. Many nodes reacting to one event means a bigger herd. Feedback loops (retries, cache invalidation) can turn one trigger into a system-wide stampede.
-
The fix is to desynchronize. Coalesce requests, use a mutex for cache refill, stagger expiry with jitter, use exponential backoff with jitter, and rate limit. Combine them where it makes sense.
-
When debugging, watch CPU, database load, cache hit rate, and latency. A sudden spike in all of these often means a herd. Break the synchronization first; adding more servers alone won’t fix it.